Evolutionary Prisoner's Dilemma Simulator
2020 | programming | haskell | [github]
I was discussing with a friend whether purely selfish behaviour is really the best way to succeed (assuming the rest of the world does not behave as such), based on the phrase “el vivo vive del bobo”. Having recently started learning Haskell, I wanted to build a basic simulator to test my hypothesis that, in a society in which members remember how each other behave, behaving selfishly (i.e. defecting) is actually less successful than cooperating).
Methodology
There are two basic units in the simulation: agents and interactions. The simulation is an evolutionary simulator and the state of the world is represented in a frame. Thus each frame contains a set of agents and the interactions which occurred in that frame (i.e. in that round of the simulation). An important aspect of the simulation is that the resulting interactions in a given frame depend on those of previous frames.
An interaction is created when two agents act together. An agent can either cooperate with or defect from its counteragent in the interaction. During an interaction, the agents have no knowledge of what the other is doing, but the interaction function can take into account previous interactions.
The most basic interaction function (“reactor”) is a simple “eye for an eye” reaction, in which the agent repeats the action taken by the counteragent in the last frame. Therefore if the counteragent cooperated in the last frame, then the agent will cooperate; if the counteragent defected, it will defect.
In order to make the simulation more realistic, however, agents were parametrised along two scales: selfishness and generosity. Selfishness is a measure of the likelihood that a given agent will defect no matter what was done in the previous frame, and generosity is the likelihood that, in the case in which the counteragent defected in the last frame, the agent will, nonetheless, cooperate. The simulation world also introduces a “mistake factor”, which is the probability that, while intending one action, an agent actually takes the opposite action.
In order to measure the effectiveness of each combination of parameters, each agent is assigned a score which is computed over the interactions in that frame and added to the score the agent inherited from the previous frame. This models the fitness of a given strategy in an evolutionary system. The scores are computed using a fixed scoring matrix (called a “rewards vector”). This has a scoring increment for each of the possible outcomes of an interaction between an agent A and a counteragent B:
A cooperates, B cooperates -> RewardsVector x _ _ _
A cooperates, B defects -> RewardsVector _ x _ _
A defects, B cooperates -> RewardsVector _ _ x _
A defects, B defects -> RewardsVector _ _ _ x
To additionally model how a real-world evolutionary scenario might work, agents can reproduce according to an encoded set of “reproductive assumptions”. This assigns a minimum and maximum probability to an agent reproducing itself (which spawns a new agent with the same parameters), and also defines the scaling function which translates an agent’s score (or fitness) to the probability that it reproduces. An important aspect of reproduction in this system is that child agents inherit the scores of their parents. This is designed to model real-world inheritance patterns.
The simulation runs with an initial size and a fixed number of
iterations, outputting a CSV of agents for each frame. This can then
be visualised using a python script. At present the parameters of the
world, which set how agents are generated, the rewards vector, and
reproductive assumptions, are hardcoded into the source (and can be edited in
Main.hs).
To therefore run a simulation with sixteen initial agents over fifty frames and
output the data into a directory called myworld_data, and then to produce
plots of those data, one would use the following script:
mkdir myworld_data
stack run myworld 16 50
cd visualise
poetry run visualise ../myworld_data
Results
In order to test the system a flat distribution of agent parameters was used, and the following world parameters:
World {
mistake_rate=0.1
, initial_size=read initialSize -- script argument
, iterations=read iterationCount -- script argument
, generator=genEvent -- flat distribution [0 .. 1]
, rewards=RewardsVector 1 (-2) 2 (-1)
, reproduction_assumptions=basicReproAssumptions
}
basicReproAssumptions = ReproductionAssumptions {
minReproProb = 0.1
, maxReproProb = 0.9
, getMinScoreScale = (/ 2)
, getMaxScoreScale = (* 2)
}
The first frame of a simulation with these parameters, sixteen initial agents, and fifty frames gave the following results:
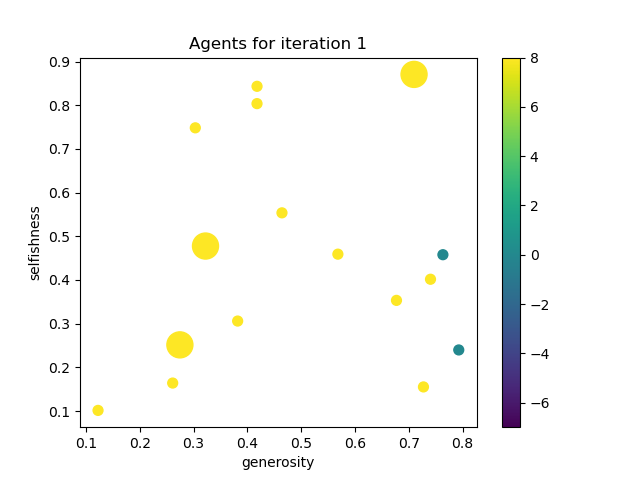
After fifty frames, the results were as follows:
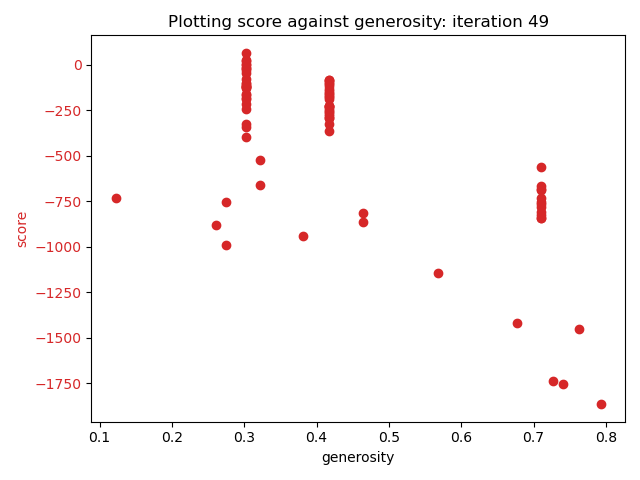
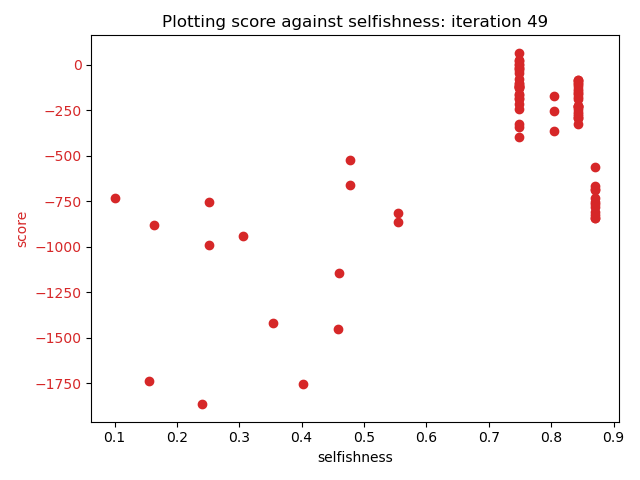
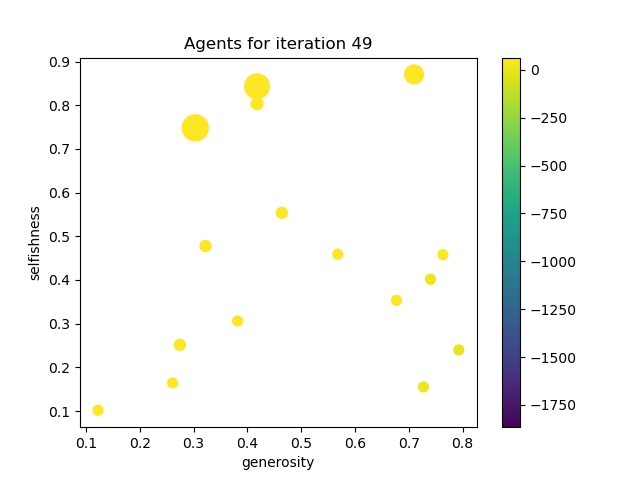
Conclusion
There were a couple of areas in which this experimental simulation was lacking. It only had flat distributions rather than normal distributions which might have been more realistic, and an interaction could only take the last frame into account, rather than a weighted history, for example. While the mechanics of the simulation feel well reasoned (if simplistic), the whole simulation is hugely sensitive to small changes in the elements of the rewards vector, which encodes a lot of assumptions. It is therefore not possible to use this simulator to really understand anything about the real world unless there is an objective derivation of those elements (which I did not find).
An interesting further experiment would be to properly test the sensitivity to the different parameters and to try to understand how that might relate to how we understand our own societies.
A final point, from a personal perspective, is that were I to write this simulator now (in 2021), having written considerably more Haskell since, it would be written very differently. This would not necessarily affect the fundamentals of the simulator, but the code would be more idiomatically Haskell-like. Nevertheless, it was a really fun way to learn some basic of the language, and really spurred my desire to keep programming in Haskell thenceforth.